
Introduction
The display of the payment pages and creation of receipt emails is done by using a series of elements known as tokens or properties. Each of these tokens is converted into a set phrase using a token dictionary when they are displayed. For example, one of the tokens used in the payment page is ‘hpp2_button_makepayment’ which is displayed as ‘Make payment’.
You can add additional language files that would allow this to display (for example) as ‘Effectuer le paiement’ in French, or to change the text displayed in English to (for example) ‘Pay now’.
You can have multiple language files within your store, and select the language to use as part of the purchase request.
Creating a language file
The language files are simply text files that can be edited using any text editor. Each line within file the represents a single token, along with the text to be displayed when this token is used. The text is separated from the token using an equals (=) sign, for example:
hpp2_button_makepayment = Make payment
There can only be one token per line. Any space or tab characters between the token and the = sign are ignored, as are any after the equal sign before the text to be displayed.
You can add comments to the file by starting a line with the hash (#) character.
It is important that you set the language name and language code correctly - if these are not set then the language may not display. The language code must be a 2 character code, and the language name should be as it would be within that language - for example, ‘Français’ not ‘French’
Examples
language_name = English
language_code = en
language_name = Français
language_code = fr
language_name = Россия
language_code = ru
You can download a file containing the complete list of tokens, and their default English language descriptions from:
https://secure.telr.com/guides/lang_en.txt
If the language file is being used only to alter existing language prompts rather than to add a new language, we recommend that it only contains the tokens that you need to change, which will allow the system to use the default values for the other tokens.
File encoding
Files must be UTF-8 or US-ASCII encoded. To avoid possible conversion errors, we would advise that characters outside of the US-ASCII range are represented using HTML numeric character entities using their Unicode value. This is done by using the following sequence:
&#UnicodeValue;
| Character | Description | Unicode value | HTML |
|---|---|---|---|
| ć | Latin Small Letter C with acute | 263 | ć |
| Ш | Cyrillic Capital Letter Sha | 1064 | Ш |
| ก | Thai Character KO KAI | 3585 | ก |
Any character for which the Unicode value is above 127 should be represented using this method.
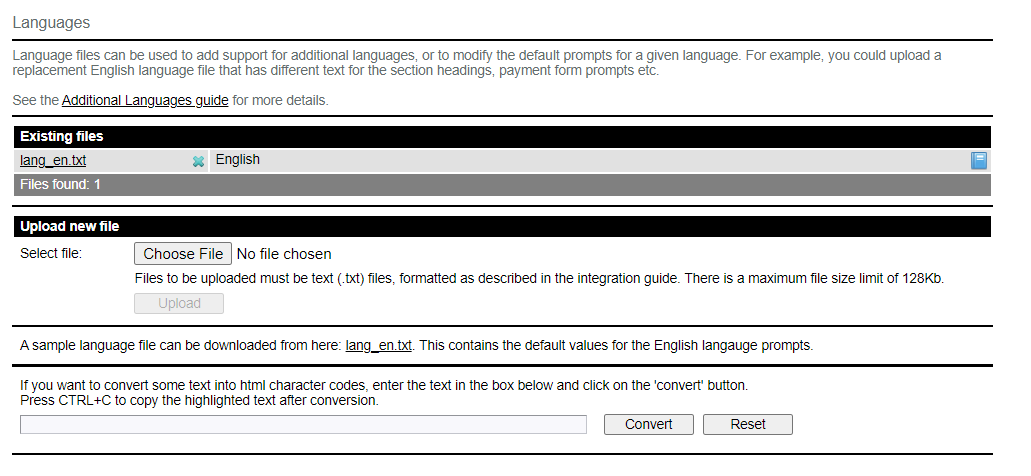
If you are unsure about converting text to HTML entities, there is a conversion utility on the language upload within the merchant administration system that can help. Simply enter the text to be converted and click the convert button. The resultant text using HTML entities will be shown, and automatically selected. Just press CTRL+C to copy the selected text to your clipboard, and you can then paste that text into the language file.

Uploading a language file
From within the Merchant Administration System, got to the ‘Integrations’ menu, select the Payment Page V2 section, and click on ‘Languages’
This will display a page showing any existing language files that you have already uploaded, and provide the option to upload a new file.
The name of the file to be uploaded is not important, other than it must be a text (.txt) file. The file will be stored on the Telr server using a name based on the language code contained within the file. For example, if the file contains ‘language_code = fr’ then it will be stored as lang_fr.txt
You can click on the name of any existing file to download it, or click on the ‘X’ icon to the side of the
name to delete it.
Specifying a language as part of the purchase request
This is done by adding an additional parameter (ivp_lang) to the purchase request containing the language code.
For example:
ivp_lang=frIf the value contained in ivp_lang is not a 2 character code, or does not match a language file uploaded to your store, then it will be ignored and the default value of ‘en’ will be used.
When sending test mode transactions, you can specify the language code ‘xx’ in which case the display of the payment page will be done without any token conversions, allowing you to see exactly where any token is used on any given page.
Time and date display
Whilst the display of time and date values sounds like straightforward actions, there are actually a wide number of different formats and styles used for this depending not only on the language in used, but also regional preferences.
For example, in the UK it is normal to format dates using the ‘day month year’ sequence, whereas in
the USA although the language is still English, the usual date format is ‘month day year’
There are a number of tokens that control how time and date values are displayed. Most of these a standard ‘token = description’ entries for setting items such as month names and day-of-week names.
These tokens include:
| Tokens starting with | Description | Examples |
|---|---|---|
| month_ | The short name for each month | month_1 = Jan, month_2 = Feb, month_11 = Nov, month_12 = Dec |
| month_ | The long (full) name for each month | month_1 = January, month_2 = February, month_11 = November, month_12 = December |
| dow_ | Days of the week | dow_1 = Sunday, dow_2 = Monday, dow_6 = Friday, dow_7 = Saturday |
| dom_ | "Day of the month using ordinal numbers." | dom_1 = 1st, dom_2 = 2nd, dom_30 = 30th, dom_31 = 31st |
There are also 6 tokens that usual special sequences to control the order that different parts of a time or date are displayed.
These control sequences are a per-cent (%) character followed by one additional character that specifies what should be displayed at this point.
For example, %H represents the hour, and %M represents minutes. So to display the time as hours and minutes separated by a colon (:) character the value of the token would be:
%H:%MWhilst many of these control sequences will display a numeric value, some can also display text. In these cases, they will refer to other tokens from within the language file to determine what to display. For example, %b represents the name of the month, so should that be February it will display whatever is held in the token ‘month_2’
A full list of the control sequences is on the following page. These sequences can only be used within the time and date tokens. They have no effect in any other token.
Control sequences
| Sequence | Displayed using | Description | Examples |
|---|---|---|---|
| %a or %A | Token: dow_ | Day of the week name | "Monday Tuesday" |
| %b or %h | Token: month_ | Short month name | "Jan Dec" |
| %B | Token: monthl_ | Full month name | "January December" |
| %d | 2 digits | Day of the month | "01 31" |
| %e | 1 or 2 digits | Day of the month | "1 31" |
| %E | Token: dom_ | Day of the month | "1st 31st" |
| %H | 2 digits | Hour using the 24 hour clock | "00 23" |
| %I | 2 digits | Hour using the 12 hour clock | "12 11" |
| %j | Digits | Day of the year | "1 365" |
| %l | 1 or 2 digits | Hour using the 12 hour clock | "1 12" |
| %m | 2 digits | Month number | "01 12" |
| %M | 2 digits | Minutes | "00 59" |
| %p | Token | AM/PM indicator (time_am or time_pm) | "AM PM" |
| %S | 2 digits | Seconds | "00 59" |
| %y | 2 digits | "Year without the century indicator" | "99 12" |
| %Y | 4 digits | "Year with century indicator" | "1999 2012" |
| %z | Digits | Time zone as offset from GMT | 400 |
| %Z | Text | Time zone | GST |
The tokens that can use the sequences are as follows:
| Token | Description | Default value |
|---|---|---|
| time_time | Display the time only | %H:%M |
| time_time_tz | Display the time with time zone | %H:%M %Z |
| time_date | Display the date | %d %b %Y |
| time_full | Display the time and date | %d %b %Y %H:%M |
| time_full_tz | Display the time and date with time zone | %d %b %Y %H:%M %Z |
| time_long | Long form (descriptive) time and date | "%l:%M %p on %A the %E of %B %Y" |
The following examples are all based on the default English language values for tokens such as month name, and are all based on the time 19:35 (7:35 PM) on the 4th of September 2011 which was a Sunday.
| Format | Additional tokens used | Displays as |
|---|---|---|
| %H:%M | None | 19:35 |
| %l:%M %p | time_pm | 7:35 PM |
| %d %m %Y | None | 04 09 2011 |
| %m %d %Y | None | 09 04 2011 |
| %d %b %Y | month_9 | 04-Sep-11 |
| %B %e %Y | monthl_9 | September 4 2011 |
| %Y %m %d | None | 2011 09 04 |
| "%l:%M %p on %A the %E of %B" | "time_pm dow_1" | 7:35 PM on Sunday the 4th of |
| %Y | "dom_4 monthl_9" | "September 2011" |
List of tokens
The token list is contained in the example English language file which can be downloaded from https://secure.telr.com/guides/lang_en.txt
Please note, this list is subject to change and there may be additions or alterations at any time.
ISO Language Codes
The languages codes used are the ISO 639-1 codes. The following table contains a sub-set of these language codes - the full list is available for download if needed.
https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes
| Lang Code | Language |
|---|---|
| sq | Albanian |
| ar | Arabic |
| hy | Armenian |
| az | Azerbaijani |
| be | Belarusian |
| bs | Bosnian |
| bg | Bulgarian |
| zh | Chinese |
| cs | Czech |
| da | Danish |
| nl | Dutch |
| en | English |
| et | Estonian |
| fi | Finnish |
| fr | French |
| de | German |
| el | Greek |
| hi | Hindi |
| hu | Hungarian |
| id | Indonesian |
| it | Italian |
| ja | Japanese |
| ko | Korean |
| ms | Malay |
| no | Norwegian |
| fa | Persian |
| pl | Polish |
| pt | Portuguese |
| ro | Romanian |
| ru | Russian |
| es | Spanish |
| th | Thai |
Whilst you don’t have to use the codes as defined by ISO 639-1, it is advisable to use them to avoid any possible confusion if additional languages are made available within the system.